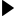
Master web monetization
with NING E-commerce
Create your personal social network and get ready to make money with its help. With NING, traffic monetization is no longer a fantasy. Monetize your blog, monetize your website, monetize your social media! It's all in your hands now thanks to NING’s new E-commerce platform.
Read moreTrusted by NING's loyal friends
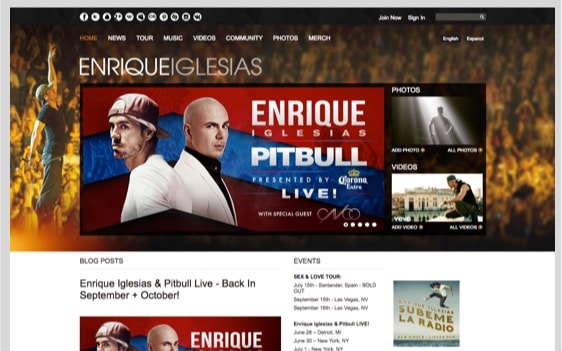
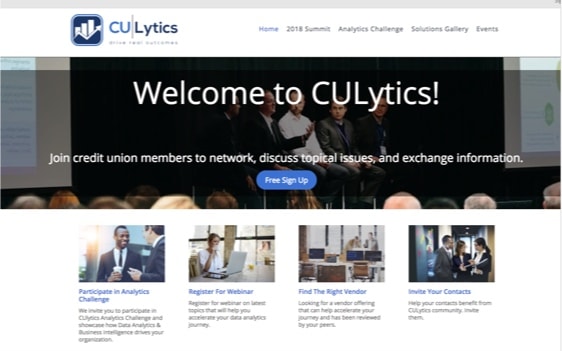
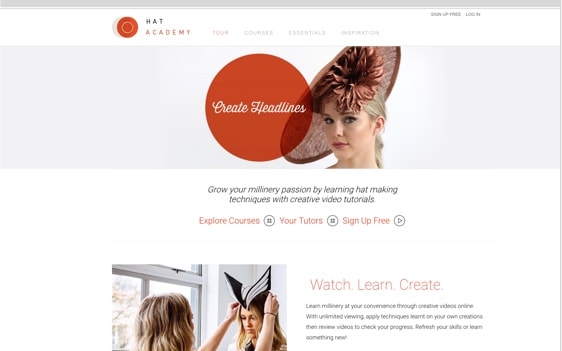
Communities of any kind find their place on NING.
See why they trust us - and follow their lead in bringing your creative ideas to reality!
Start a professional social community with minimum effort
-
No coding needed
You don’t have to be a developer - our drag-and-drop network builder empowers you to easily create a professional website in a blink of an eye.
-
Social integration
Sign up with Facebook, Twitter, Linkedin, Google and more. Pull in content from other social media and RSS feeds into your Activity Feed, to enrich multichannel communication.
-
Custom design
Want to get a mind-blowing design for your social community? Customize your network with HTML and CSS. Don’t know how to code? We will embody your wildest ideas!
-
24/7 support
Don’t know how to set up something? Or cannot find the answer in online Help Center? Contact us via email, live chat, or call us - 24/7 customer service will help you with any issue.
-
Basic features toolkit
We’ve integrated such features as Analytics, Groups, along with Blogs, Photos, Videos, Forums, and many more. If you want any extras - we are open to your suggestions!
-
Monetization option
Thinking about making money with your community? Our e-commerce module is a goldmine that allows you to drive traffic, convert visitors, sell products, post ads to monetize your network.
Helping Charitable Organizations
get their voice heard in the society
NING is here to make sure you have all the means to deliver your message and the shortcuts to do it fast. Our special offer for nonprofits presents a large opportunity to raise awareness, attract more members, build trust, and bring social value to the masses. Under the individual terms, nonprofit organizations will be able to focus on their mission - with all means to contribute to a better future.
2,000,000+ networks
have been built to date using NING!

Kyle S.
With NING, I set out to create an awesome community - it was my chance to succeed in my business and I did it.

Thomas K.
I don’t know a thing when it comes to creating blogs and such. On my NING website, I only have to come up with what I have to say to my readers, as all the organization was already done for me.

Jill N.
NING helped to embody my ideas into a real business. I draw my inspiration from my hobby - and now I'm a professional designer with my own website.



Jonathann G.
On NING, I can communicate with anyone I want. It took 3 years to grow my community - all in a good time.


Julia G.
This platform is a place where I can band people together. Being a wedding planner, I have the opportunity to surprise and bring positive emotions.

Becca M.
Educating people has always been my everything. I have no doubt that starting my community was the right thing to do. Now, I have the opportunity to share educational content, post informative video, and hold interesting events - this is something I always wanted to devote my life to.




Rachel R.
People like me are seeking the opportunity to build their online communities for nonprofit purposes. NING gave me this chance. For almost a year, I have been doing charity work, successfully implementing various social projects.